Bypassing SSRF Protection to Exfiltrate AWS Metadata from LarkSuite

Introduction:
Lark is an online, all-in-one collaborative platform offering calendar, document and chat functions. They have a public bug-bounty program at https://hackerone.com/lark_technologies , and offer good bounties with a pretty quick payout time.
This write up will detail my process of discovering a potential SSRF, and how I bypassed their existing protections to achieve full read of AWS metadata.
Part 1: Deep dive into the app!
A question I get fairly often in regards to my SSRF findings, is “How do you find them, what tools/automation do you use to discover vulnerable endpoints?!!”.
My answer to this question is always the same thing — DEEP DIVE THE APPLICATION. This can take time and effort, but will almost always be more effective than anything else. Learning the inside and out of an application allows you to identify areas which could be making external requests, or potentially vulnerable to SSRF.
This isn’t just relevant to SSRF issues by the way, the secret to finding bugs in general is to know the application.
When searching for SSRF bugs, I try to look for anything where the functionality requires making external requests. Some common web app features I look for include:
- Chats/ Messaging — Some modern chat features will render a preview of any links sent in chat.
- PDF/File Conversion features — Any feature that offers converting user-controlled content to file types like PDF . Definitely check out Owning the clout through SSRF and PDF Generators if you haven’t already.
- File Uploads — Any form of file upload. Things like crafted SVG files can result in SSRF if rendered server-side. Upload Scanner is a great Burp (Pro only) extension that can help with finding these vulnerabilities in uploads.
- Import from file — Features that let you “import content from” files . Excel docs, Word docs, Zip files , etc. These often require some form of server-side processing. Office docs like Excel and Word are basically archives containing multiple XML files. Modifying the XML files can result in XXE/SSRF when the document gets processed server-side.
- Hidden Stuff — SSRF can be found in hidden parameters or requests that aren’t glaringly obvious just by using the application. It’s important to go through the Burp Proxy logs and manually look for any request that may be returning data from a URL. The Param Miner Burp (free) extension is useful for finding hidden parameters/functionality.
There are many more similar things to keep an eye out for, but these are just a few examples of what I look for.
During my “deep dive” of the Lark application, one area in particular piqued my interest for SSRF testing. The Wiki feature had the following option to import content from 4 different document types:

When provided a file, the application would add it’s content to a new Lark Wiki page. This seemed like a good area to test for SSRF, since there was likely some server-side processing of the provided file.
Part 2: Testing the Import from docs feature
The first thing I attempted was achieving XXE/SSRF via importing the Microsoft Office documents. My thought was that maybe the XML in the documents would get processed allowing external entities. If this was the case, I could’ve potentially exfiltrated info such as file/url contents.
My attempts at XXE ultimately failed despite trying multiple payloads/bypasses. I won’t go in depth about this topic, but if you’re interested more about exploiting XXE in Office documents, check out this awesome writeup— Exploiting XXE with Excel .
After some further testing, I ruled out exploiting anything in the Office Documents. Now there were 2 options left to import from — CSV and Confluence ZIP files . CSV is pretty boring and not likely to require much processing, so I started to focus on the Confluence file.
Confluence gives users the option to Export their pages. One of the options to export as is a ZIP file that will contain the HTML content for each page. An example export looks like this inside:

Each page is represented as an HTML file, and any images/attachments/styles are stored locally then referenced by the HTML file. This is an example snippet of HTML where an attachment is being used as an image within a Confluence page:

Whenever a Confluence zip is uploaded to Lark, any images included in the original Confluence page will be uploaded/added to the generated Lark Wiki page .
The highlighted parts of the the above image interested me , because Lark’s processing included this image in it’s created Wiki page. The thought came to my mind — what if I change this path to an actual URL instead, will it grab images from any URL?!!
In order to test my theory, I modified the image sources to point at my Burp Collaborator domain, like so:

Then I saved the modified HTML ,added it back to the ZIP , and imported to Lark. To my surprise not only did I receive a hit to my Collaborator, but the generated Lark Wiki page contained a downloadable attachment with the full response body from the Collaborator.

This meant that the provided URL did not even have to be an image, any URL’s contents would be fully exfiltrated as an attachment into my Lark Wiki page. A potential full-read SSRF , but only if I could hit anything internal to prove impact.

The IP that hit my Burp Collaborator came from AWS, so I immediately had the idea to try and exfiltrate information from the metadata URL (169.254.169.254). I again modified my file as the following:

If this was successful, an attachment would be generated containing the output from the metadata URL. I saved the file and imported my ZIP. This time though , unfortunately no attachment was created . Seemingly some sort of SSRF protections existed, preventing me from hitting internal ips or domains .
Part 3: Bypassing the protections
After initially failing to hit anything internal, I decided to do some subdomain enumeration for Lark domains to try hitting internal ones and proving impact that way. I collected a list of subdomains then tried exfiltrating the content from any domain I couldn’t hit publicly. Unfortunately, this method did not work either. I was still unable to exfiltrate information from anything internal.
My next thought was to try redirects. If you’ve read my previous write up Just Gopher It, then you already know I love redirects. Redirects are often a fantastic way to bypass certain SSRF protections.
My process of testing redirects in this case was the following:
- Set up a redirect script that will 302 redirect traffic from my server to AWS metadata URL…
- Modify the Confluence Page’s image URL to point at my server…
- Save/Import the zip to Lark and hope the redirect is followed…
- If redirect is followed and bypasses their protections, attachment gets generated with contents of their metadata URL.
Unfortunately this plan didn’t work out either. I verified that redirects are being followed, but redirecting did not bypass any of their protections…I still could not hit anything internal by this method.
At this point I was running out of options and ideas. It started frustrating me , and I was on the verge of just considering it an “unexploitable ssrf” and moving on. After taking a break from it for a while though, I finally had that light bulb moment - DNS Rebinding!

Now I’ll be the first to admit usually my “light bulb moments” end up being completely incorrect and resulting in me getting my hopes up over absolutely nothing, but in this case I was actually spot on.
To put it super simply, DNS rebinding allows you to have a hostname that switches between 2 ips with a very low ttl. This can bypass SSRF protections by resolving as a “safe” ip at first, then immediately switching to an “unsafe” or internal ip.
The website https://lock.cmpxchg8b.com/rebinder.html can be used to easily generate a DNS rebinding domain. In my testing I used the following rebinder domain: 8efb23ae.a9fea9fe.rbndr.us, which switches between a Public Google IP & Internal AWS Metadata IP:
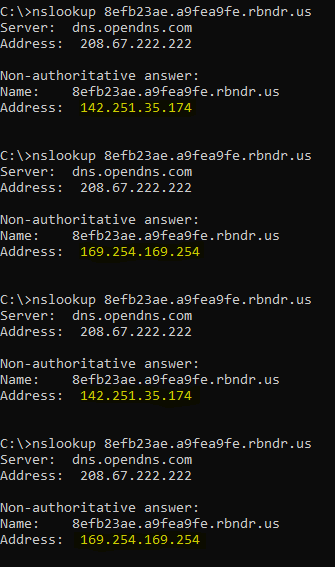
Using my DNS rebinding domain, I updated the URL for image sources:

I saved my Confluence zip file , then imported it to Lark Wiki ,fingers crossed I would get an attachment . I didn’t get an attachment at first, but realized that with the randomness of the DNS rebinding it may require multiple imports to succeed.
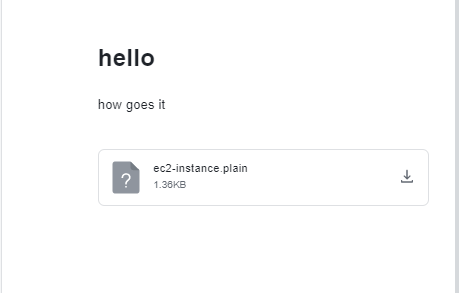
About 10 import attempts later my theory proved to be correct — The DNS rebinding finally worked to bypass protections and the generated Lark wiki contained an attachment with a directory listing from their metadata URL !
By using this DNS rebinding method to access the metadata URL http://169.254.169.254/latest/meta-data/identity-credentials/ec2/security-credentials/ec2-instance , I was able to successfully exfiltrate AWS credentials for the ec2 instance.
I submitted the report for this issue and they resolved it almost immediately after triage. Within a few days of my report being triaged, I was given bug bounty for a critical finding! The Lark team has been great to work with on this issue, and I highly recommend their program for anyone who does bug bounty hunting.
